阿里云破纪录的背后:377秒是如何炼成的?
10月28日,Sort Benchmark官方宣布,阿里云用377秒完成了100TB的数据排序,打破了此前Apache Spark创造的1406秒纪录。在含金量最高的GraySort和MinuteSort两个评测系统中,阿里云分别在通用和专用目的排序类别中创造了4项世界纪录。
消息一出,整个技术圈都沸腾了,特别是对云计算高度关注的互联网、计算机行业。阿里云打破世界纪录,再次点燃了大家对分布式计算的热情。同时,大数据、云计算的各种圈子里也掀起了讨论:这件事情有多难?怎么做到的?对普通人意味着什么等等。
基于这些原因,我们发表此文,希望从阿里云的角度回答大家的疑问。
这件事情有多难?
SortBenchmark的出现,是希望能用最简单的方法,评估出不同的计算模型,计算平台的计算能力优劣?而排序是最基础的计算问题,任何一本数据结构和算法的计算机教材,首先要讲的,就是各种排序算法。所以排序,当之无愧的成为这个简单,但直接有效的benchmark。
SortBenchmark竞赛最早的纪录追溯到1987年,当时都是单机的比赛。如何造出最强大的机器,如何尽量压榨单台机器的性能是大家的主要工作。
但从1998年开始,大家的策略和思路发生了改变,分布式计算开始成为主流。大家的工作重点也转变为:如何有效调度成百上千乃至几万台机器上的CPU、内存、网络、磁盘IO等物理资源,最快完成海量数据的排序。这就像军队里,管好几个人,你可以当班长;管好几十个人,你可以当排长;但要管好几万人,你才能当将军。
而且,对大规模集群做线性扩展,远比大家想象得困难。正如,一个班长说“我只有几个人,所以我才是班长,但如果你现在给我几万人,我马上就是将军了”,大家会觉得好笑一样。当规模不断扩大,系统的各种瓶颈都会逐渐出现,原来能处理所有消息,能做出各种调度决定,现在发现忙不过来;如果找出下级代理,可能又会发现代理做出的决定和处理总不是最好的。
这还只是一种资源的调度,当计算需要多种资源完美配合时,你可能会发现内存是有效调度了,但是会影响网络的使用;网络可能用好了,但是又影响了磁盘的有效利用。调度不好时,各个维度可能互相冲突。
当你把资源调度得差不多了,你可能发现其实这个计算任务如果从机器A上换到机器B上运行,时间会短很多。或者机器A本来很适合,但是碰巧机器A坏了,就像几千人的军队打仗,有人临阵脱逃很正常。诸如此类的问题,随着规模的不断扩大,会急剧复杂化。可以说,规模每增加一个数量级,分布式计算平台需要处理问题就会完全不同。而如何利用大量低端机器达到高性能,正是云计算技术的核心挑战。
阿里云的“飞天”分布式计算平台于2013年正式上线了5000台的单集群规模,现在生产线上的规模更大。关于如何支持这么大的规模,可以参考VLDB 2014上伏羲发表的文章,这不是本文的重点。本文接下来会重点介绍在支持如此大规模计算集群后,我们还做了哪些事情,让一万亿条记录,100TB数据的排序能在不到7分钟完成。
阿里云如何做到的?
“飞天”是阿里云的分布式计算平台,不仅承担着阿里集团内部所有的离线数据处理任务,同时也提供阿里云公共云服务的基础平台支撑。“飞天”系统的关键模块包括:(a)Pangu-分布式文件系统,负责存储和管理计算中心的数据文件;(b)Fuxi-分布式调度系统,负责管理计算中心的集群资源,调度分布式系统中运行的在线和离线应用。Fuxi提供了一种名为FuxiJob的大数据批处理框架,能处理任意的基于DAG(有向无环图)描述的用户计算任务。
Fuxi已经部署在了阿里巴巴多个计算中心的数十万服务器上,单个集群的规模超过5000台机器。任何可以用DAG描述的离线数据处理作业都可以用Fuxi Job来执行,包括但不限于MapReduce作业和更加复杂的机器学习作业。Job的输入输出文件以及运行过程中的临时文件都存储在Pangu中,依赖Pangu提供的文件副本和locality配置来获取更好的性能,同时提高数据的可靠性。
接下来我们重点介绍基于“飞天”系统开发的Fuxisort程序。我们在GraySort和MinuteSort两项比赛中使用相同的程序,程序中的优化将在后续章节中详细介绍。
1. 概述
首先,程序会对待排序数据进行采样,以确定数据各分片的范围。如图1所示,除了采样之外,整个数据排序过程分两大阶段:map阶段和sort阶段。两个阶段都包含多个并行的任务。
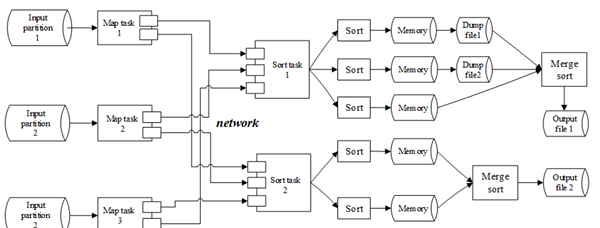
图 1. FuxiSort流程图
在map阶段,map任务通过Pangu的ChunkServer进程从本地磁盘中读入数据分片,然后对输入数据进行RangePartition分配给不同的sort,分配后的数据通过网络直接传输给sort任务。
在sort阶段,所有的sort任务周期性地将map任务发过来的数据读入内存,当内存缓冲区满的时候,进行基于快速排序算法的内存排序,内存排序的结果数据将会被写入Pangu的temporary文件(这种文件存放在本地,不会做多份的拷贝)。当sort任务接收完所有的map数据后,会将所有在内存中排好序的数据以及之前写入temporary文件中的数据一起做归并排序,归并排序的最终结果输出到Pangu中。当FuxiSort所有的sort任务都执行完后,会生成多个的Pangu文件,它们在全局也是有序的。
2. 实现和优化
a)输入数据采样。为了降低数据倾斜带来的性能影响,我们对输入数据做了采样,根据采样结果来确定RangePartition的边界,从而保证每个sort任务处理的数据量尽量接近。
举例说明,假设输入数据被分成了X个文件,首先,我们在每个文件里随机选取Y个位置,从每个位置开始连续读取Z个数据样本,最后共得到X * Y * Z个样本。然后,我们对这些样本数据进行排序,排序后样本数据被均分为S份,这里S为sort任务的个数,这样就得到每个sort任务待处理数据的范围边界。由于样本是均分的,可以使得每个sort任务都处理了几乎相等的数据量。
对于GraySort而言,我们有20000个输入文件(X),每个输入文件选取300个位置(Y),每个位置读取1个样本(Z),最终我们选取6000000条样本进行排序,并均分为20000份(sort任务个数),map任务将根据上述样本来进行RangePartition,保证 sort任务处理的数据尽量均匀。整个采样过程大约耗时35秒。对于MinuteSort而言,3350个输入文件,我们在每个文件里选取900个数据作为样本,总的样本数量为3015000,排序后分成10050份。整个采样过程耗时4秒。对于IndySort,则不需要这个采样过程。
b)IO 双buffer。map阶段,FuxiSort在一个I/O buffer中处理数据,同时Pangu在另一个buffer中执行数据读入操作。这两个buffer的角色会周期性地进行切换,这样就能保证处理数据操作和I/O操作能并行起来,从而能够大幅降低任务的Latency。
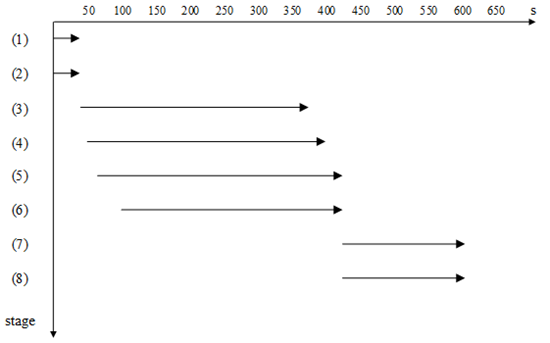
图2. FuxiSort各阶段启动顺序
c)流水线操作。如图2所示,为了进一步降低整体Latency,我们把排序过程的每个阶段分解成许多小的步骤,并且尽可能地将这些小的步骤重叠起来执行。这些分解出来的小步骤如下所示:
- 数据采样;
- Job启动;
- MapTask读输入数据;
- MapTask发送数据至SortTask;
- SortTask接收数据;
- SortTask将内存中的数据进行排序,当内存装不下时,将排好序的数据dump到临时文件中;
- SortTask将内存中的有序数据和临时文件中的有序数据做merge sort;
- SortTask写最终输出文件。
FuxiSort将数据采样过程和Job启动过程并行起来执行,在Job启动阶段做的主要工作包括任务的分发,以及一些其他的数据管理工作,比如收集所有SortTask的网络地址,并且通知所有的MapTask。当数据采样过程结束时,采样程序会将每个分区的界限存放在Pangu上,并且会建立另一个通知文件存放在Pangu上,用来标志采样结束。一旦任务分发完成,每个MapTask就开始周期性地检查通知文件是否存在。一旦检查到通知文件存在,也就意味着采样程序产生的各分区界限可用,MapTask就会立刻读取这些分区界限,并且根据这些界限进行数据分发。
步骤(3)(4)和(5)在map阶段并行执行,步骤(7)和(8)在sort阶段并行执行。
在步骤(6)中,只有当分配给task的内存已经全部填满,才会进行排序和dump,由于在排序过程中,内存被全部占用,没有剩余内存可以接收新的数据,因此步骤(5)会被阻塞。为了缓解这个问题,我们将步骤(5)和(6)并行起来,一旦内存使用超过一定量值,就开始做排序,这样,步骤(6)会被提前执行,而步骤(5)也不会被阻塞。当内存全部占满时,我们将内存中已经排好序的数据进行归并,并dump到临时文件中。显然,开始做排序的内存阈值越低,步骤(6)开始得越早。在我们的实验中,当接收到的数据占用分配给Task内存的1/10时,开始执行步骤(6)。通过这种方法,我们将I/O和计算并行起来,并且没有明显的延迟,虽然这种方法可能会需要merge更多的临时文件,但在我们的场景中没有因此导致明显的overhead。
图2说明了每一步所花费的时间以及在执行过程中这些步骤之前的重合部分。
d)网络通信优化。在map task和sort task之前有明显的网络通信流量,每个网络包到达后都会产生CPU中断。如果对中断的处理被绑定到一个指定的CPU内核上,当这个CPU内核忙于排序时,对中断的处理会被延迟,这就可能导致请求超时,甚至丢包。通过设置”sm_affinity”,可以将网络中断产生的负载均衡到所有的CPU内核上,请求超时和丢包的比率明显下降。
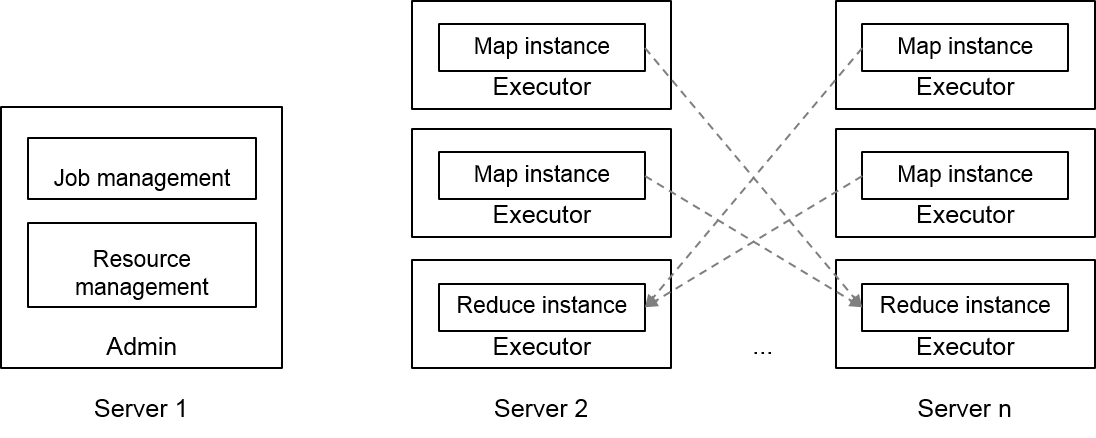
图三. 实时计算框架
e) 对MinuteSort的进一步优化。由于MinuteSort的执行时间要求限制在60秒内,一般离线作业的调度开销就变得不容忽视。为了降低这些开销,我们在Fuxi的准实时Job模型上执行MinuteSort,Fuxi准实时Job模型是为了降低调度产生的overhead,使内存计算获得很高的性能而开发的。Figure 3说明了准实时Job模型的框架。在典型的生产环境中,准实时系统是一个长期运行的service,会在集群部署过程中被启动,并且在每台机器上启动一个不退出的worker进程。系统启动之后,用户可以向准实时系统的调度器提交各种job,并且可以获得job在运行期间的状态。sort benchmark竞赛要求与排序直接相关的启动和退出过程也需要包含在最终的时间里,为了遵守这一规则,我们在提交MinuteSort job之前,先通过程序去启动准实时系统worker,在job运行结束后,再将worker进程停掉,在最终提交的结果中,包含了worker启动和停止所用的时间。
准实时系统针对的场景是在中等规模大小的数据集(不超过10TB)上,对延迟敏感的数据处理过程,在这种规模的数据集下,包括输入和输出在内的所有records都可能被cache在内存中。在我们的实验中,我们只在准实时系统中运行MinuteSort。
对普通人意味着什么?
从2009年阿里云诞生那天起,我们的愿景就是打造一个自研的、通用的、大规模分布式计算底层系统,让计算像电一样成为公共服务,“飞天”平台是承载这一理念的技术核心。
FuxiSort打破Sort Benchmark排序比赛世界纪录是阿里云6年技术沉淀的直接体现,但这仅仅是开始。技术本身不是目的,阿里云在任何技术上的进步,都会通过云产品对外输出,让中国乃至全世界的云计算客户收益。比如本次参赛的FuxiSort,通过开放数据处理服务(Open Data Processing Service, 简称ODPS)对外商用。ODPS是由阿里云自主研发,提供针对TB/PB级数据、实时性要求不高的分布式处理能力,应用于数据分析、挖掘、商业智能等领域。阿里巴巴的离线数据业务都运行在ODPS上(详情参考http://www.aliyun.com/product/odps/ )。
阿里云将借助技术创新,不断提升计算能力与规模效益,希望更多的合作伙伴、中小企业、开发者能够受益于云计算带来的便利和价值,共同将云计算变成真正意义上的公共服务和普惠科技。


相关文章
文章评论
-
-
-